Manual handling of multimodal assets is slow and error-prone.
Many teams receive customer questions and assets (voice notes, images, PDFs, spreadsheets) through messaging channels like WhatsApp, but lack an automated, consistent way to parse the content, extract structured information, index it for search, and answer follow-ups with context. Manual handling is slow, error-prone, and doesn't scale.
End-to-end multimodal intake and retrieval.
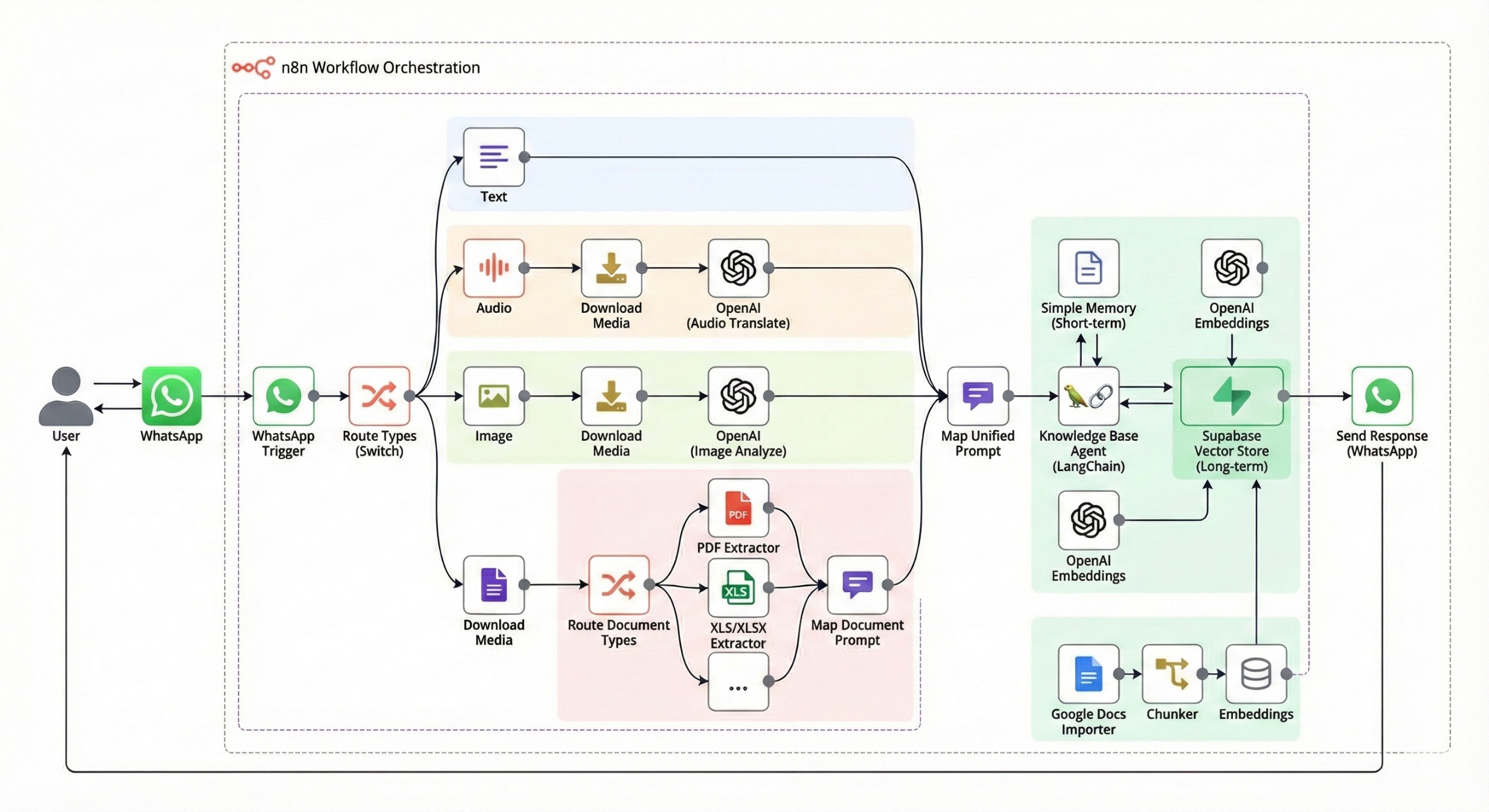
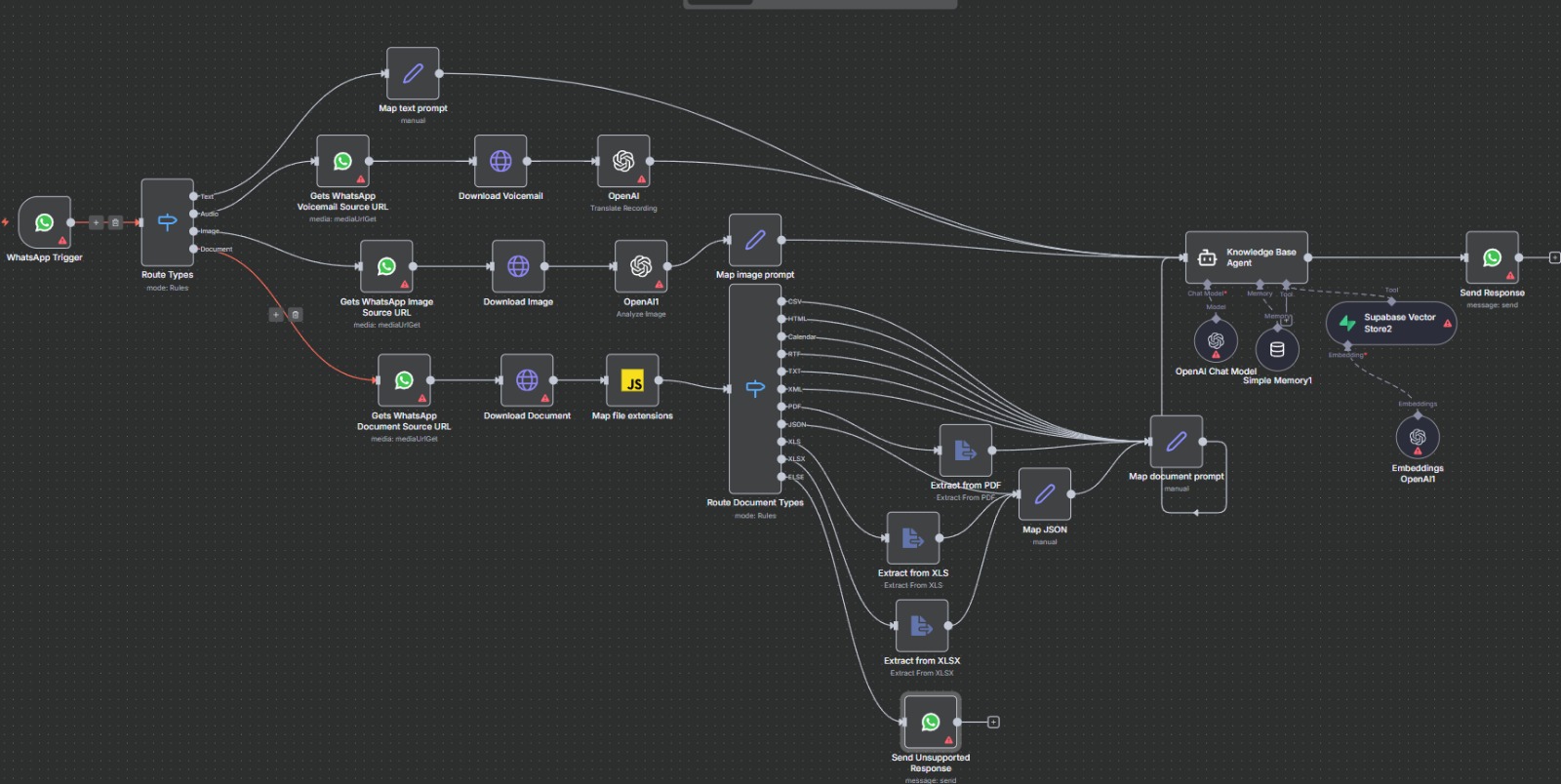
This n8n workflow automates end-to-end multimodal intake and retrieval: accepts messages from WhatsApp (text, audio, image, document), routes media by type, uses OpenAI multimodal APIs to transcribe audio and analyze images, extracts document content, normalises prompts, generates embeddings, and stores them in a vector index. A LangChain-style Knowledge Base Agent with short-term memory retrieves context and answers user queries via WhatsApp.
Phase 1: Multimodal Intake & Routing
The system receives a WhatsApp webhook, inspects the message type (text/audio/image/document), and routes to the appropriate processing branch.
It then downloads the raw media bytes. Type-specific processing kicks in: OpenAI audio translate for voicemail, image analyze for visual content, and native extractors (PDF/XLS/XLSX) for documents.
Phase 2: Structured Extraction & Embeddings
A switch node routes documents by MIME type; specialized extractors output a unified JSON schema.
OpenAI embeddings are generated and stored in a MongoDB Atlas vector collection (`data_index`) for semantic retrieval.
Phase 3: Knowledge Base Agent
The LangChain-powered agent receives the unified prompt, consults the vector store via a `productDocs` tool, references a short-term memory buffer (keyed per WhatsApp user ID), and uses `gpt-4o-mini` to compose context-aware answers.